skysafe-datalake
SkySafe : Comment nous avons construit un Data Lake pour traquer les vols aériens en temps réel et détecter les anomalies grâce au Machine Learning
Par Tahiana Hajanirina Andriambahoaka, Mohamed Amar et Lounis Hamroun · Février 2026
Projet réalisé dans le cadre du cours DATA705 — BDD NoSQL à Télécom Paris
Chaque jour, des milliers d’avions survolent la France. Avec les orages, les descentes brutales des avions, les vitesses anormalement faibles en altitude : comment repérer automatiquement en quelques secondes les vols à risque ?
C’est la question que nous nous sommes posée en lançant SkySafe. Un pipeline Big Data qui ingère en quasi temps-réel les positions GPS de tous les avions au-dessus de la France, les croise avec la météo locale, calcule un score de risque pour chaque vol, et utilise le Machine Learning pour détecter automatiquement les comportements suspects.
Toutes les informations nécessaires au suivi des vols sont regroupées dans un unique dashboard Kibana : chaque avion y apparaît avec ses principales données, un indicateur de vols normaux ou à risque, ainsi que la mise en évidence des anomalies détectées.
Dans cet article, découvrez la conception de ce système, les principaux obstacles rencontrés, et les solutions mises en place pour les surmonter.
L’Architecture : un pipeline en 4 étapes
Avant de plonger dans les détails, voici la vue d’ensemble. Notre pipeline suit le modèle Raw → Formatted → Enriched → Usage, orchestré par Airflow et alimenté en parallèle par deux sources de données :
API Vols (OpenSky) ──> Nettoyage / Formatage (Spark) ──┐
├─> Croisement + ML (Spark) ──> Elasticsearch
API Météo (Open-Meteo) ──> Nettoyage / Formatage (Spark) ──┘
Les principaux outils qui font tourner ce pipeline :
- Apache Airflow : le chef d’orchestre qui déclenche le pipeline toutes les minutes et gère toute la coordination entre les différentes tâches.
- Amazon S3 : stockage centralisé de toutes les données brutes (JSON) et transformées (Parquet).
- Apache Spark (PySpark) : moteur de traitement responsable du nettoyage, de la normalisation, du croisement des données et du calcul des scores de risque.
- Elasticsearch : base de données qui indexe les données enrichies pour la recherche en temps réel et la visualisation dans Kibana.
Les sources de données
Pour construire notre système de surveillance, nous avions besoin de deux types d’informations : où sont les avions et quel temps fait-il là où ils volent.
Les vols : OpenSky Network
L’API OpenSky Network nous fournit en temps réel la position de chaque avion grâce à son transpondeur ADS-B : identifiant ICAO, callsign, latitude, longitude, altitude, vitesse, cap, taux de montée/descente, pays d’origine…
Nous filtrons les vols sur une bounding box couvrant la France métropolitaine pour réduire le volume de données à traiter.
Pour un usage non commercial, nous avons droit à 10K requêtes quotidiennes gratuitement, ce qui est largement suffisant pour notre cas d’usage.
La météo : Open-Meteo
L’API Open-Meteo nous donne les conditions météorologiques actuelles pour 6 zones stratégiques couvrant la France métropolitaine : Paris CDG, Toulouse, Lyon, Marseille, Nantes et Lille.
Nous avons sélectionné ces 6 villes car elles constituent les grands noeuds du trafic aérien français : ce sont des zones à forte densité de vols, où les conditions météorologiques ont le plus d’impact sur la sécurité aérienne. Elles sont également géographiquement bien réparties sur l’ensemble du territoire, ce qui permet de couvrir des microclimats différents.
Pour chaque station, on récupère la température, le vent, les rafales, la pluie, la visibilité, la couverture nuageuse et le code météo (qui indique notamment la présence d’un orage).
Par défaut, les utilisateurs anonymes disposent de 400 crédits API par jour. En créant un compte et en effectuant des requêtes authentifiées, nous avons pu bénéficier de 4 000 appels par jour — largement suffisant pour interroger ces 6 stations toutes les minutes.
L’idée est que pour chaque avion en vol, on lui associe les conditions météo de la station la plus proche grâce à la formule de Haversine (distance sur la sphère terrestre), puis on en déduit un niveau de risque.
Le défi inattendu : quand l’API refuse de coopérer
C’est ici que les choses sont devenues intéressantes.
Durant les premières phases de développement, tout fonctionnait parfaitement en local : l’API OpenSky répondait en quelques secondes. Mais dès que nous avons déployé notre pipeline sur un serveur cloud (une instance EC2 AWS), les requêtes ont commencé à échouer avec des erreurs 504 Timeout.
Après investigation, nous avons identifié le problème : OpenSky Network impose des limites de débit strictes et bloque activement les requêtes provenant des gros datacenters. Notre serveur se trouvait sur une plage d’adresses blacklistée. C’est d’ailleurs assumé publiquement dans la documentation officielle de leur API :
“Note that we may block AWS and other hyperscalers due to generalized abuse from these IPs.”
Il fallait donc trouver une solution alternative pour contourner ce blocage, sans pour autant rapatrier le code en local. C’est là que l’architecture Serverless est venue à la rescousse.
Notre solution : une fonction Serverless comme relais
Nous avons contourné le problème en déployant une fonction serverless (Lambda) sur Scaleway Cloud. Cette Lambda agit comme un proxy intelligent :
- Notre pipeline Airflow sur AWS envoie un appel à la fonction serverless au lieu d’interroger OpenSky directement.
- La fonction serverless, hébergée sur une IP non bloquée, interroge OpenSky à notre place.
- Elle filtre les résultats et nous renvoie les données prêtes à l’emploi.
Ce contournement a résolu le problème immédiatement — et nous a permis au passage de mettre en pratique l’architecture Serverless. Une pierre, deux coups.
Le Score de Risque : transformer la météo en indicateur de danger
Après avoir nettoyé les données et associé chaque vol à sa station météo la plus proche, Spark calcule un score de risque composite de 0 à 100 basé sur des règles aéronautiques officielles (FAA) :
| Condition météorologique | Points | Justification |
|---|---|---|
| Orage détecté | +40 | Dangers cumulés : turbulences extrêmes, givrage, cisaillements de vent. La FAA recommande de ne jamais approcher un orage sévère à moins de 20 nm. |
| Rafales > 80 km/h | +25 | Le Wind Shear déstabilise la portance et rend le contrôle difficile. |
| Précipitations > 5 mm | +20 | Visibilité réduite et aérodynamisme des ailes altéré. |
| Visibilité < 1 000 m | +20 | Passage obligatoire en conditions IFR (Instrument Flight Rules) — alerte majeure pour le contrôle aérien. |
| Altitude < 300 m en vol | +15 | Marge de récupération quasi nulle face aux cisaillements de basse couche (LLWS). |
| Couverture nuageuse > 80 % | +10 | Plafond bas masquant le développement de nuages d’orage. |
Sources officielles utilisées pour définir ces règles métier :
- Orages et turbulences : FAA Advisory Circular 00-24C - Aviation Weather
- Cisaillement de vent (Wind Shear) : National Weather Service (NWS) - Aviation Safety
- Règles de visibilité et météo en vol : FAA - Pilot’s Handbook of Aeronautical Knowledge (Chapitre 12)
Un avion traversant un orage avec rafales et mauvaise visibilité atteint facilement 80+ → HIGH RISK, affiché en rouge sur le dashboard. Un vol en croisière par temps clair obtient 0 → LOW.
Limite du score : il croise météo et position, mais ne dit rien sur le comportement de l’avion lui-même. C’est là qu’intervient le Machine Learning.
Machine Learning : détection automatique des phases de vol et des anomalies
C’est la brique qui transforme notre pipeline de données en véritable système de surveillance intelligent — et celle dont nous sommes le plus fiers.
Le constat : l’API ne dit pas tout
L’API OpenSky fournit la vitesse, l’altitude et le taux de montée/descente de chaque avion — mais elle ne dit rien sur sa phase de vol (décollage, croisière, atterrissage), ni sur d’éventuels comportements anormaux. Ce sont pourtant des informations essentielles pour un système de surveillance aérienne — et c’est précisément de là que vient le nom SkySafe : un ciel surveillé et plus sûr.
Nous avons donc entraîné un modèle de Machine Learning non supervisé directement dans Spark, capable d’inférer automatiquement ces informations à chaque exécution du pipeline — soit toutes les minutes.
K-Means : classer les phases de vol
Nous utilisons l’algorithme K-Means (disponible nativement dans Spark MLlib) pour regrouper les avions en 3 clusters à partir de trois caractéristiques : vitesse, altitude et taux de montée/descente. Pour visualiser : imaginez tous les avions disposés sur une table. Le K-Means va naturellement les regrouper en trois tas :
- Groupe 1 — Faible vitesse, basse altitude → Décollage / Atterrissage
- Groupe 2 — Vitesse moyenne, altitude variable, fort taux de montée → Montée / Descente
- Groupe 3 — Vitesse élevée, haute altitude, taux vertical quasi nul → Croisière
La labellisation est automatique : les clusters sont triés par altitude moyenne croissante. Le cluster le plus bas devient “Takeoff / Landing”, le plus haut “Cruise”, et le troisième “Climb / Descent”.
En amont du K-Means, un StandardScaler normalise les trois features. Cette étape est indispensable car sans normalisation, l’altitude (exprimée en milliers de mètres) dominerait entièrement le calcul des distances, reléguant la vitesse et le taux vertical à un rôle quasi nul.
Limitation du K-Means et mécanisme de fallback
Le K-Means génère toujours $k = 3$ clusters, quelle que soit la distribution réelle des données. En pratique, cela pose problème aux heures creuses (2h–5h du matin), quand le trafic se réduit quasi exclusivement à des long-courriers en croisière : l’algorithme segmente alors artificiellement une population homogène en trois sous-groupes non significatifs.
Pour pallier cette limite, nous basculons automatiquement sur une classification par règles aéronautiques lorsque les trois centroïdes sont trop proches (clusters non significatifs) :
- Altitude < 300 m et vitesse < 60 m/s → Décollage / Atterrissage
- Altitude > 3 000 m et taux de variation verticale quasi nul → Croisière
- Cas restants → Montée / Descente
Ce mécanisme assure une classification cohérente en toutes circonstances : K-Means en période normale, règles métier en période creuse — sans dégradation de la qualité des données.
Détection d’anomalies : identifier les comportements de vol suspects
Une fois les clusters constitués, chaque avion se voit associer un centroïde de référence qui est le point central de son groupe. Nous calculons la distance euclidienne entre chaque avion et ce centroïde : c’est l’anomaly_score. Plus cette distance est grande, plus le comportement de l’avion s’éloigne de la norme de son groupe.
Le seuil de détection est recalculé dynamiquement à chaque cycle selon la formule moyenne + 2 écarts-types sur l’ensemble des distances observées — ce qui correspond statistiquement aux 5 % de vols les plus atypiques.
Le Résultat : un dashboard en temps réel
Toutes ces données enrichies arrivent dans Elasticsearch, puis s’affichent sur un tableau de bord Kibana. Voici ce que nous obtenons :
- Carte interactive — Les avions sont représentés sur une carte de la France métropolitaine, avec un code couleur (vert / orange / rouge) reflétant leur niveau de risque calculé à partir du croisement entre leurs données de vol et les conditions météorologiques locales.
- Répartition des phases de vol — Un diagramme circulaire affiche la composition du trafic en temps réel : quelle proportion d’avions est en croisière (Cruise), en décollage/atterrissage (Takeoff / Landing) ou en montée/descente (Climb / Descent) ?
- Distribution des scores — Histogrammes du score de risque et de l’anomaly score, pour visualiser la distribution et identifier les seuils critiques.
- Tableau détaillé et filtrable — Callsign, pays d’origine, altitude, vitesse, score de risque, phase de vol, statut d’anomalie. On peut cliquer sur n’importe quel avion pour voir ses détails.
- Anomalies — Les vols à score élevé (> 80) et les comportements atypiques détectés par le modèle ML sont mis en évidence dans le tableau, pour une identification rapide.
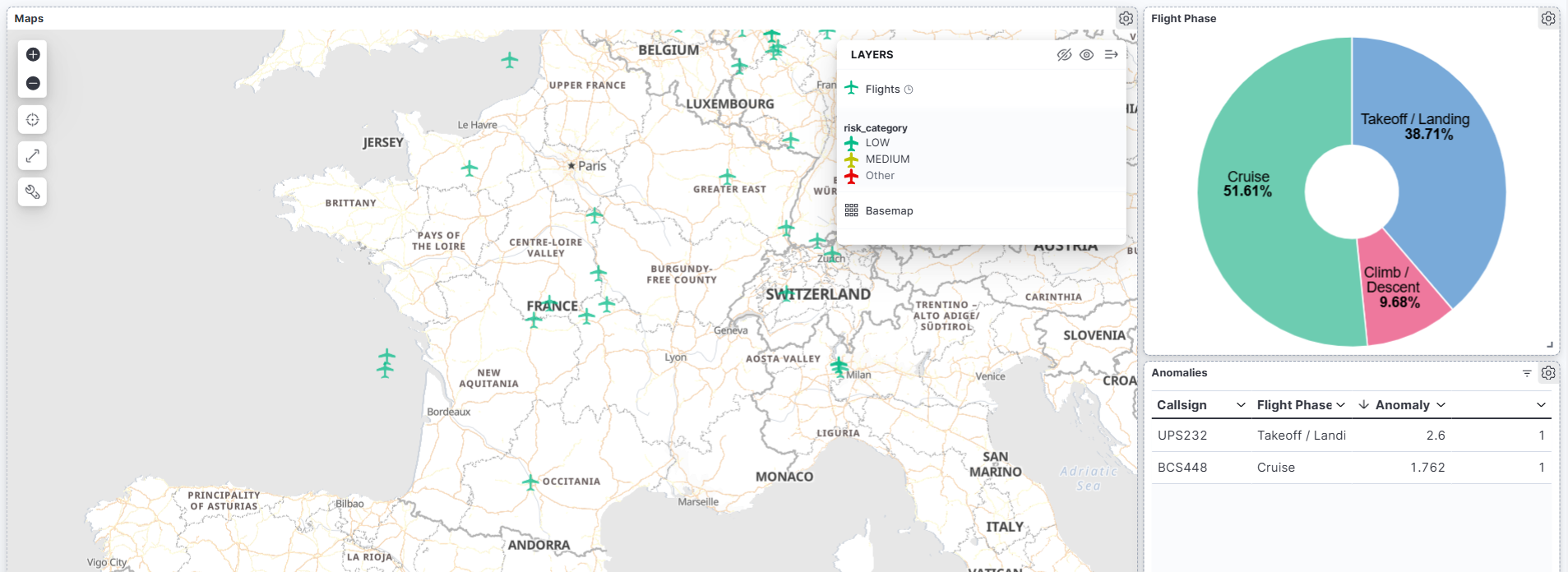
Le dashboard est importé automatiquement au premier lancement grâce à un second DAG Airflow qui attend que les premières données soient indexées dans Elasticsearch, puis injecte la configuration Kibana via l’API Saved Objects (pas d’intervention manuelle).
Dans les coulisses : les détails d’implémentation
Voici les choix techniques concrets qui rendent le pipeline robuste en production :
- Tout est conteneurisé : un seul
docker-compose uplance les 6 services (PostgreSQL, Airflow webserver, Airflow scheduler, Elasticsearch, Kibana, init container). Aucune installation manuelle. - Zéro secret dans le code : les credentials AWS, OpenSky et Airflow sont stockés dans un fichier
.envlocal, exclu du dépôt Git via.gitignore. Le code source peut être rendu public sans risque. - Données partitionnées sur S3 : chaque fichier est stocké sous la forme
s3://bucket/<layer>/<group>/<dataEntity>/date=YYYY-MM-DD/hour=HH/. Spark lit directement la dernière partition sans scanner l’ensemble du bucket. - Horodatage systématiquement en UTC : dès l’étape de formatage Spark, toutes les dates sont converties en UTC. Cela évite les décalages temporels lors du croisement entre les données de vol (OpenSky) et les données météo (Open-Meteo), qui proviennent de fuseaux horaires différents.
- Mise à jour par clé ICAO dans Elasticsearch : l’identifiant ICAO de l’avion sert de clé d’indexation. À chaque cycle, Elasticsearch met à jour le document existant s’il existe, ou en crée un nouveau sinon — le dashboard Kibana reflète toujours l’état le plus récent, sans accumulation de doublons.
Les leçons apprises
Ce projet nous a confrontés à la réalité du Big Data bien au-delà des tutoriels :
- Les APIs peuvent vous trahir en production. OpenSky nous a bloqués dès le déploiement sur AWS, et c’est en cherchant un contournement — déployer une Lambda Scaleway comme proxy — que nous avons le plus progressé sur les architectures distribuées et serverless.
- Le Machine Learning non supervisé est puissant, mais fragile face aux cas limites. Le K-Means produit toujours exactement k clusters, même lorsque les données n’en forment qu’un seul. Notre approche hybride (ML + règles métier en fallback) nous a enseigné qu’un système robuste en production ne peut pas reposer sur un seul modèle : il faut anticiper ses zones d’échec et prévoir une stratégie de repli cohérente.
- Spark est redoutable à condition de rester dans son écosystème. En s’appuyant exclusivement sur des transformations natives — et en évitant les UDF Python qui cassent les optimisations du moteur — notre pipeline traite l’ensemble des vols actifs en quelques secondes, avec une empreinte mémoire minimale.
- Docker Compose simplifie radicalement le déploiement. Conteneuriser l’intégralité du projet permet à n’importe qui de le cloner et de le lancer en une seule commande, sans configuration manuelle — ce qui facilite aussi bien la reproductibilité que le partage.
Reproduire le projet
Le projet est entièrement open source et disponible sur GitHub — SkySafe-DataLake.
Le dépôt contient toutes les instructions nécessaires pour le lancer dans votre propre environnement. Vous y trouverez le détail des prérequis, la configuration des variables d’environnement et les étapes de démarrage pas à pas.
Merci de nous avoir lus jusqu’ici !
Si ce projet vous a intéressé ou si vous avez des questions, n’hésitez pas à nous laisser une petite étoile sur le repo GitHub ⭐ ou à nous contacter.
Bon vol ! ✈️
Projet SkySafe — DATA705 BDD NoSQL — Télécom Paris — Février 2026